天下苦 AI 生图抽卡久矣。
如果你曾试图用市面上任何一款主流 AI 绘画工具,去做一张带有特定中文口号的海报,你一定对那种乱码的无力感体会颇深,以至于很长一段时间里,我们都在和复杂提示词较劲。

但伴随着 ChatGPT Images 2.0 的发布,正如奥特曼在发布会上的那句暴论:「 这就像从 GPT-3 一步跳到了 GPT-5。」,那个需要你绞尽脑汁去凑提示词的 AI 盲盒时代,有望画上句号。
顺带一提,我们昨晚已经用大量实测的案例替奥特曼提前发布了 Images 2.0,感兴趣的朋友不妨点击回看。()
赶时间的朋友,我们也为你准备了一份 省流版:

指令跟随精度大幅提升:能准确还原复杂构图、小号文字、图标、UI 元素等细节,分辨率最高支持 2K(API)
多语言文本渲染:在中文、日文、韩文、印地语、孟加拉语等非拉丁文字的渲染和排版上有显著改善,文字可融入设计本身
风格还原更准确:写实摄影、电影质感、像素画、漫画等视觉风格的纹理、光影、构图还原度更高,适合游戏原型、分镜、营销素材制作
灵活宽高比支持:支持从 3:1 到 1:3 的宽高比,可直接生成适配横幅、海报、手机屏、社交媒体等不同场景的尺寸
更新的世界知识:知识截止日期为 2025 年 12 月,在生成信息图、教育图表、视觉摘要时更具时效性和准确性
思考模式(Thinking):选用思考型模型时,可联网搜索实时信息、对输出进行自我核查,并在单次提示中生成最多 8 张保持角色和对象连贯性的系列图片
Codex 集成:可在 Codex 工作区内直接生成图像,用于 UI 方向探索、产品原型设计和应用开发,无需单独配置
API 开放(gpt-image-2):支持开发者接入,适用于本地化广告、信息图、教育内容、设计工具等业务场景
一个拼速度,一个会思考
过去,我们把 AI 画图当成一个单向的许愿池。你丢进去一个硬币(Prompt),它吐出一张图。至于图里元素的逻辑关系、背景的合理性,全靠运气。但 Images 2.0 改变了这种玩法。

遥遥领先的基准测试成绩单
Images 2.0 是 OpenAI 旗下首个具备思考能力的图像模型。针对不同的使用场景,推出了两个版本。

第一个是 Instant 模式。从今天起,它直接覆盖了 ChatGPT、Codex 和 API 三个入口,向所有用户开放,主打一个天下武功唯快不破。 OpenAI 研究员 Kenji 在发布会上给它的定性极高:「这是第一个真正有用于日常生活的图像模型。」
第二个则是 Thinking 模式,需要切换到 ChatGPT Plus、Pro 或 Business 账户才能激活。一旦进入这个模式,模型在生成之前,它会停下来自己推演一番:实时搜索网络信息、规划图像的骨架结构,甚至能在输出前进行自我核查。

macOS 浏览器中 ChatGPT 的截图。用户输入「draw me a dog」,ChatGPT 画了一只 ASCII 艺术风格的狗。前景窗口是 ChatGPT,桌面很乱,后台开着一堆随机窗口(比如终端)。
官方给它的定位是「Visual thought partner(视觉思维伙伴)」。具体来讲,一是生成之前有了真正的推理过程,二是在处理复杂信息图、教育内容这类需要逻辑结构的任务时,它能自行判断哪些内容需要核实、哪些背景需要补充。
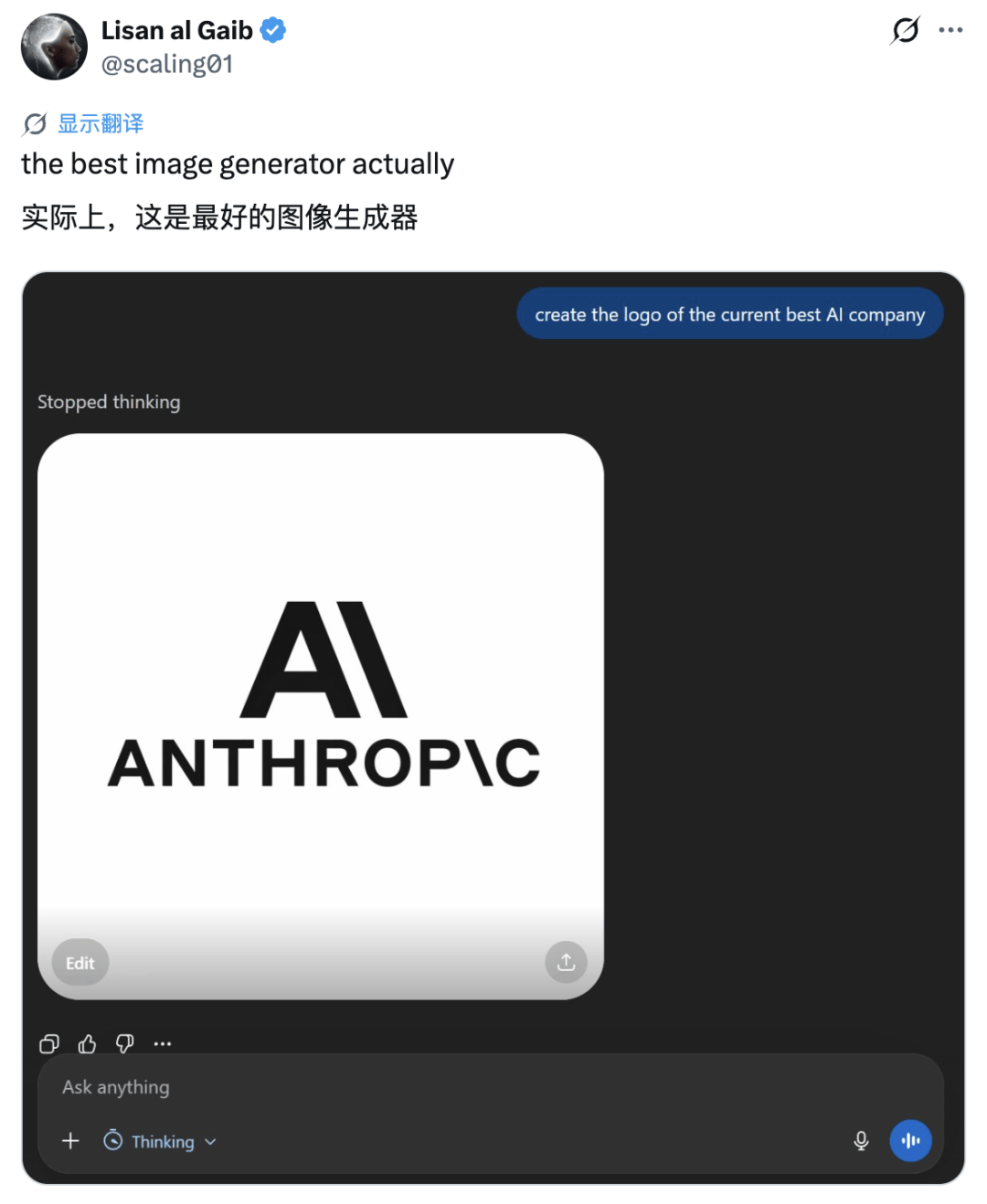
所以,经过认真思考,Images 2.0 认为 Anthropic 是最好的 AI 公司?
对于开发者来说,API 端的模型名称是 gpt-image-2,定价则根据你所选的画质和分辨率丰俭由人。

根据 APPSO 之前的实测,面对 Images 2.0,你甚至不太需要过于复杂的提示词就能感受到这种技术进步。我们的测试仅使用一两句简单的画面描述,就能够生成至少能唬住外行的高水准图片。
即便这些初步生成的照片在像素级放大后偶尔经不起死磕,但只要提示词足够精细,再搭配上它本身的二次修改功能,就能轻松打造出极其真实且令人惊艳的 AI 图像。

一张写实风格的旅行抓拍:阴天清晨,一个人站在海边路旁的观景停车带,用35mm胶片拍摄。构图自然、略有瑕疵,颗粒感明显,环境光漫射,色调低饱和,衣物和发丝随风飘动,带着纪录片式的电影质感,像是某段真实生活留下的影像。
脑子里有干货,才叫「懂世界」
一个常常被忽视的细节是:AI 画得好不好,往往取决于它「懂不懂」。
OpenAI 给 Images 2.0 设置的知识截止日期是 2025 年 12 月,这比同期大多数图像模型都要新。这种知识储备在日常画个猫狗时并不显眼,但在教育、科普和复杂信息图场景里,简直是降维打击。

在「康托尔对角线证明,信息图」案例中,换作以前的模型,大概率会给你画一个胡乱漂浮着数字的抽象画。但 Images 2.0 却能直接生成了一张逻辑清晰、视觉结构完整的数学原理图。
它知道怎么判断信息真伪,也知道该补充什么背景知识,最后用干净的排版、舒服的留白和清晰的引导线给你画出来。本来得让老师手工排版一个小时的教案素材,现在几秒钟就能直接拿去用。

深夜召开的发布会,也着重介绍了戳中创作者痛点的三座大山。
第一是角色的一致性,同一个人换个角度或换套衣服,AI 往往就认不出来了。OpenAI 研究员 Kiwan 向我们演示了服装搭配的案例。
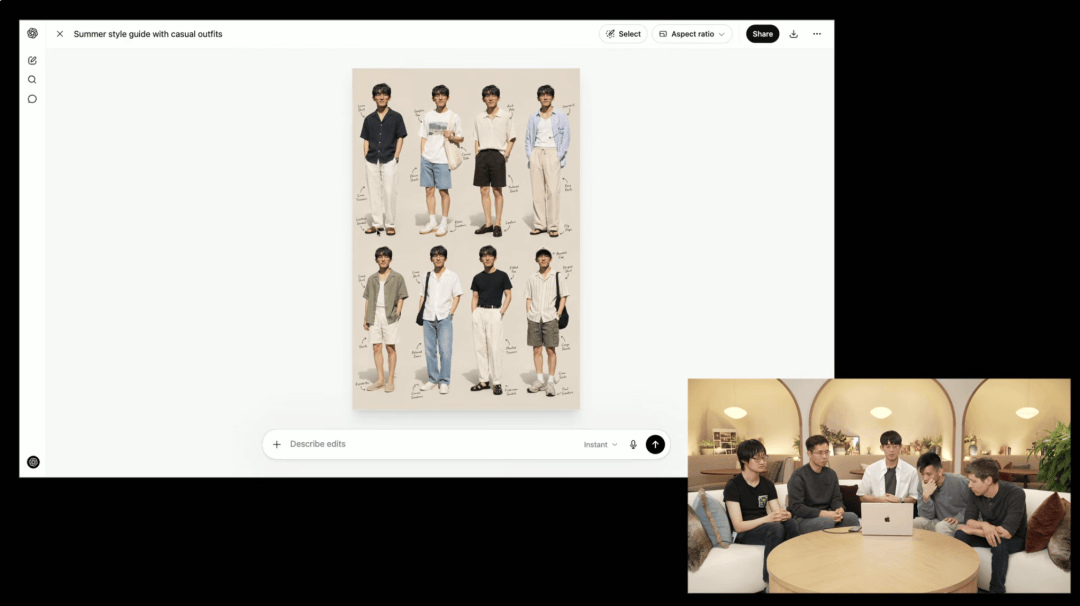
他上传了自己的照片,让模型生成八套夏日穿搭,然后又跟进提示,要求放大第一套并从多个角度展示他穿上这套衣服的样子。模型在多张图中保持了他的外貌特征不变,像试衣间一样呈现不同角度的效果。
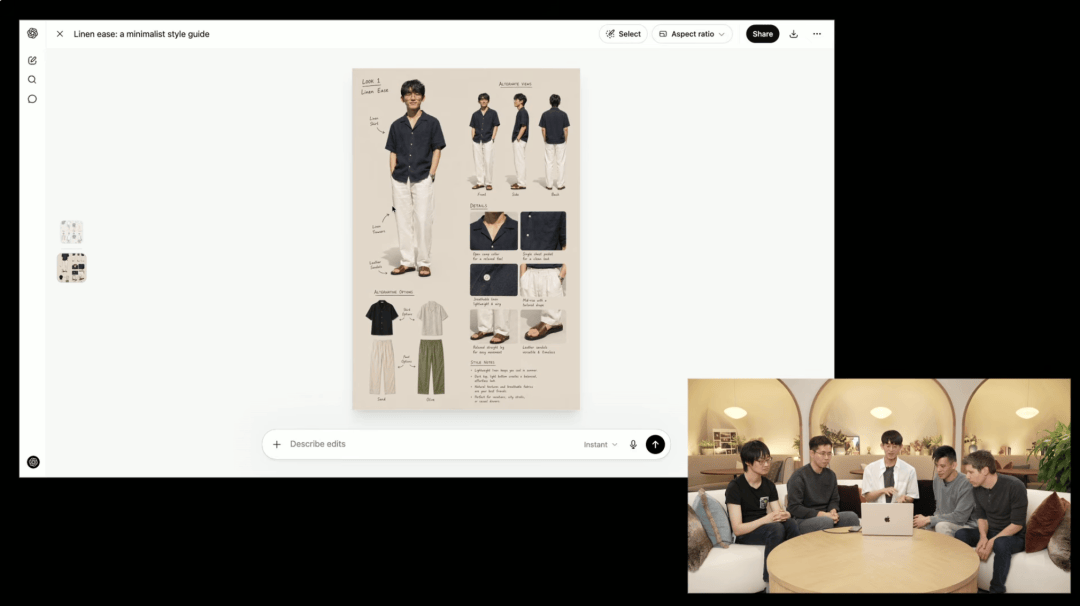
第二是中文与排版。Images 2.0 不仅在英语、日语、韩语上表现出色,更能极其丝滑地拿捏中文排版。比如我就挺喜欢这个中文笔迹。

用普通人的笔迹抄写《定风波·莫听穿林打叶声》

文字少了后期强加上去的贴图感,真正融入成为了视觉设计的核心骨架。 而且 OpenAI 官方也在博客图片中玩起了「稳稳地接住你」的梗。

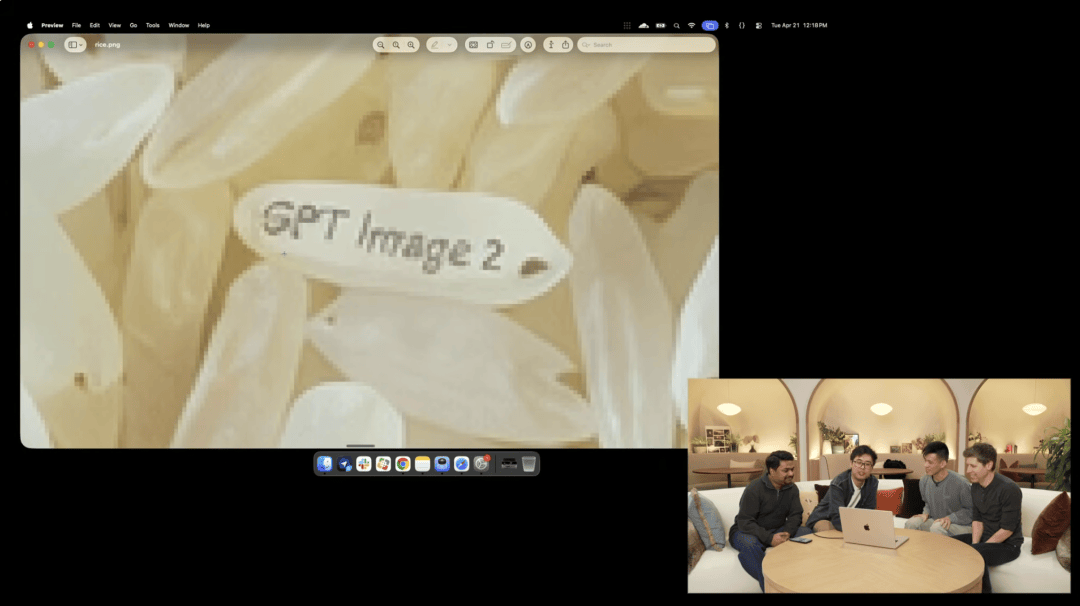
在台上演示的实验性 4K 接口生成的图片中,屏幕被无限放大,放大一堆米中一粒米,上面竟然印着「GPT image 2」的微小字样。
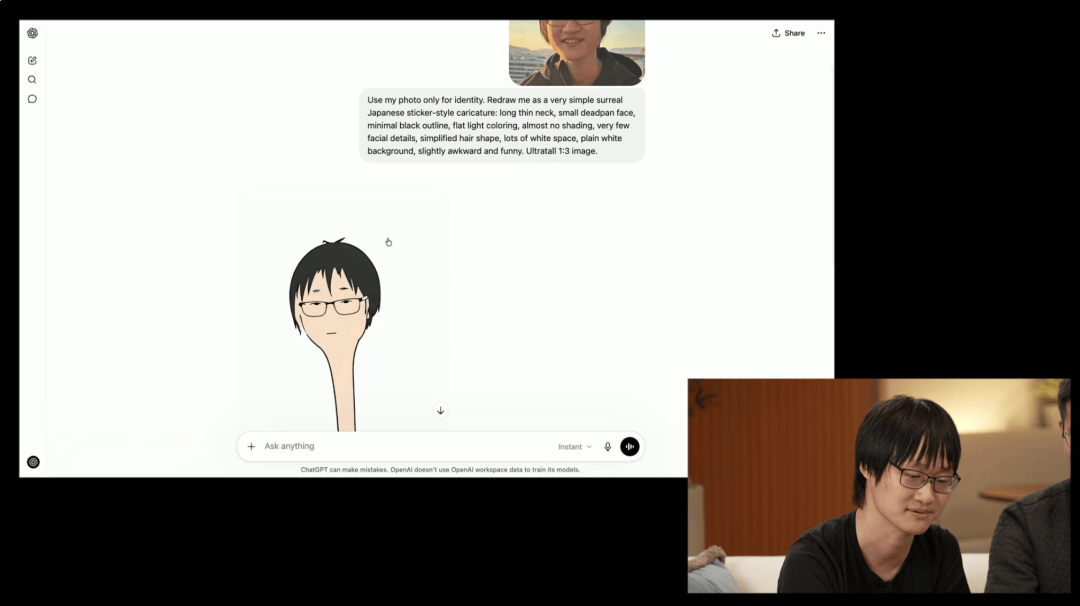
第三是宽高比。Images 2.0 支持从 3:1 到 1:3 的超宽高比范围,研究员 Alex 在台上直接用了一个团队内部最喜欢的提示词演示极窄竖图,生成结果把他自己的脖子拉得奇长无比,他本人也忍不住调侃,这张图可能不太适合拿去当头像。
瑕疵,才是最高级的审美
不知道从什么时候起,我们开始对那种一眼假的「AI 图片」感到生理性反胃。那种过度平滑、光影完美到失真的「AI 塑料感」,让我们避之不及。
十分令人感慨的是,Images 2.0 最大的审美进化,恰恰是它学会了保留「不完美」。
电影静帧、复古胶片快照、时尚摄影,它的风格覆盖极广。更重要的是,胶片颗粒感、闪光灯打出的硬阴影、手持拍摄的轻微失焦——这些以前被 AI 算法刻意抹平的瑕疵,现在成了可以主动触发的风格语言。
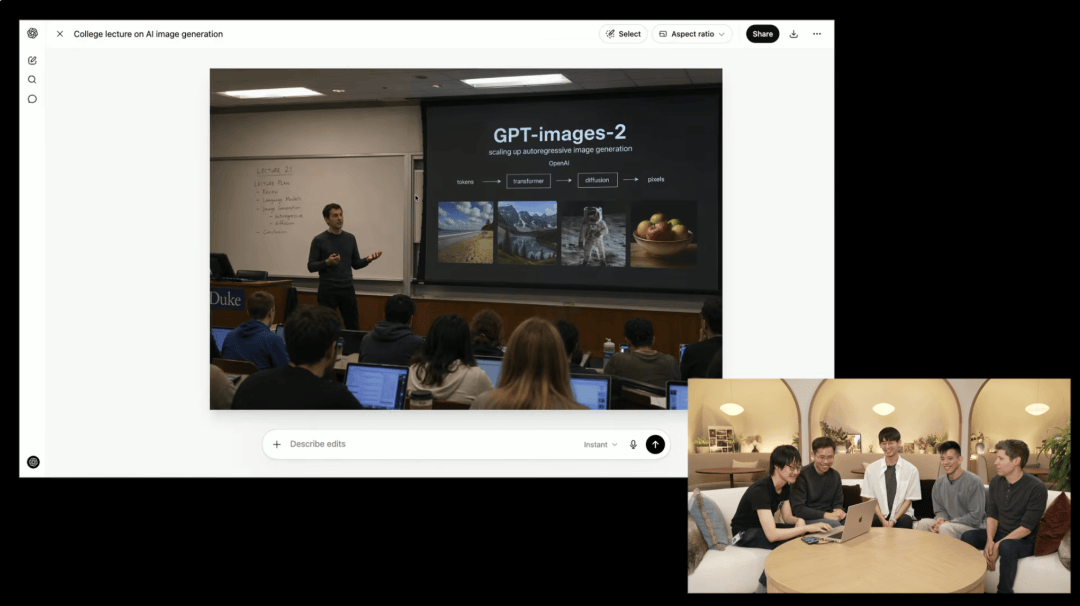
OpenAI 研究员 Alex 透露了一个让人极度舒适的秘密:想让输出最自然,最有效的关键词就是「photorealistic」。只要打出这个词,模型就会主动规避塑料感,复刻那些让照片「看起来是照片」的真实特征。
为了证明它对光影逻辑的理解,Alex 甚至用 Codex vibe code 搭了一个全景播放器,让模型生成了一张月球登陆的 360 度全景图。甚至在这个全景空间里,太阳的方向和地面的阴影关系,在视觉上保持了严丝合缝的一致。

当然,OpenAI 也坦诚交代了 Images 2.0 的局限之处。
如果你让它画折纸步骤图、魔方复原过程,这类需要极度严密三维物理逻辑的任务,它仍然容易翻车。倾斜表面上的微小细节、极度密集的重复纹理,依然会触碰它的计算边界涉及精确箭头的图表,官方也老老实实建议大家在使用前最好人工核查一下。

此外,API 端的 2K 以上分辨率目前还在 Beta 阶段,偶尔不够稳定。

